
Editor’s note: this article is based on an internal memo Will wrote for our Professional Services team called Default to Deploy. It’s reproduced here with minimal edits to make it suitable for an outside audience. There has always been a lot of debate about the best ways for companies to incorporate testing into their marketing, and where teams should sit on the pragmatic–dogmatic spectrum. This memo lays out the SearchPilot approach, and the ways we advise our customers to use their test data and results.
When a test is based on a strong hypothesis, and yet our analysis is failing to reach statistical significance for our chosen level of confidence, we should make a consulting-style call on whether to recommend that the customer deploys the change to their whole site / section.
In many cases, where we believe that we are improving the site, or making it more discoverable from information retrieval first principles, and where the cost is not prohibitive, we should default to deploy with the objective of compounding many small gains and taking our customers’ sites to states that will be valued more highly by the search engines in the future. We are aware that there are many possible small uplifts that we cannot detect with statistical confidence. The primary purpose of testing in many cases is to avoid deploying changes that have a negative impact while moving quickly and deploying proven and likely winners.
This is because we are doing business, not science. In scientific environments, high confidence in the result, and the ability to extrapolate from our discoveries are the priority. In business, we are typically seeking to beat the competition and should make decisions incorporating our prior beliefs, on evidence much closer to balance of probabilities, and using the test data mainly to justify the costs of changes and to avoid the damaging effects of negative impacts.
We can summarise all this as follows: we are here to help our customers capture any competitive benefit available, statistically significant or not. Default to deploy.
Contents:
- Consulting with data in hand
- Motivations
- What we’re hoping for
- Potential downsides
- External validation / discussion
Consulting with data in hand: what to do when we don’t reach statistical significance
We will generally want to run all tests for at least some consistent time before attempting to make a call. This is based on our assumption that all real effects will take some time to be visible because of the need for a recrawl / reindex. After that point, when we would expect to start seeing whatever results we are going to see, we should start considering pragmatic decisions.
When in the top half of the quadrant below, we should weigh the benefits of quick decisions to deploy with the benefit of waiting for more data to get higher confidence or greater certainty of the magnitude of the uplift. The top half is about balance of probabilities, avoiding drops, and winning in the long run, while the bottom half is more about justifying the cost of the change and getting ROI data.
Note: strength of hypothesis in what follows is subjectively-defined as it will depend on context, but a good way of thinking about it is that strong hypotheses are those that are like recommendations we might make in a consulting environment where we couldn’t test and had no specific data on likely success.
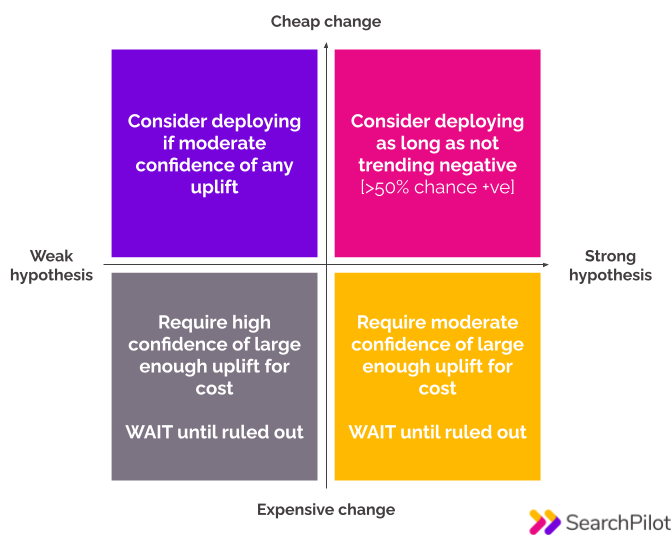
How we should think about different situations that haven’t reached statistical confidence
When we have reached statistical significance on a test, we can say things like:
“Our model shows this test is statistically significant at the 95% level. The best estimate our model shows for the uplift is 12%, or 7,000 organic sessions / month when rolled out to the whole site section.”
It’s very common, however, to find ourselves in a situation where a test has not reached statistical significance. In these cases, I argue that we should behave differently in each of the four quadrants above depending on the combination of costliness of change and strength of hypothesis. Here are some examples of how we might think about a test in each quadrant:
Pink quadrant - strong hypothesis / cheap change
“We can’t declare a winner in this test with statistical confidence, but the results show that it is more likely to be a winner than to be a loser. This change has a relatively low cost to deploy, and is based on a relatively strong hypothesis meaning we have a prior expectation of a long-run neutral-to-positive impact so we should consider deploying.”
Purple quadrant - weak hypothesis / cheap change
“It looks unlikely that we are going to be able to declare this test a winner at the 95% confidence level, and we should be cautious about drawing general conclusions from it since it wasn’t based on a strong prior belief that this should be a positive change. Having said that, there is only a X% chance of a neutral or negative change resulting in this outcome, and the possible upside is as much as Y% uplift so we should deploy if we are comfortable with the risk.”
Orange quadrant - strong hypothesis / expensive change
“It looks unlikely that we are going to be able to declare this test a winner at the 95% confidence level, but the best estimate from our model is a substantial uplift of Z%, and the hypothesis is strong. We should compare the likely uplift to the expected cost to deploy.”
Grey quadrant - weak hypothesis / expensive change
We only recommend deploying this kind of change when we reach true statistical significance.
Recommending rollback
We might recommend rolling back (not deploying the change we tested) for any of four reasons:
- This test has shown with statistical confidence that the change will have a negative impact
- While not reaching statistical significance, the data shows it is more likely damaging than helping
- The scale of the potential uplift is too small to justify the cost / maintenance of this feature
- This is a risky or costly change and the range of uncertainty is simply too wide to make a call to deploy based on this data
Motivations: “it’s inconclusive, so rollback” is a tempting recommendation
We are all discovering as we go what the most effective recommendations are in a test-driven SEO world. We want to find ways of thinking and communicating that make customers happy and align with our way of driving effective, accountable search results. We should be seeking to serve customers’ genuine best interests with the best recommendations we can make.
The reason I started thinking about this particular angle is that I noticed a trend as we started having more and more people across the company running tests, analysing data, and making recommendations to our customers. In write-up after write-up, I saw different consultants say some variation of “this test is inconclusive, so we should roll it back”. In particular, the thing that most motivated me to think about how we could do this better was seeing us make that recommendation when our statistical analysis showed an upwards trendline that was never going to reach statistical significance at the 95% level but that was indicating that we’d predict an uplift on the balance of probabilities.
We are doing business
In the long run, we aim to be successful by giving our customers a genuine competitive advantage. At the margin, if we have to choose between being certain something brings an uplift, or capturing any uplift that is there, we should choose the latter especially when we believe there is only a small chance of a negative impact.
When we are competing against consulting recommendations made without testing, our biggest wins come from never deploying losers as well as deploying winners. We can beat non-data-led consulting with a strategy of “only deploy winners” but that should lose over time to a strategy of “deploy winners plus strong inconclusive results”.
What we’re hoping for
Beyond customer relationship benefits / risks, I see two primary effectiveness reasons for taking the kind of pragmatic approach I describe here:
1. Capturing uplifts smaller than we can measure
We know that there are uplifts that are too small for us to detect with statistical confidence - both in theory and in practice. There is a world of marginal gains that are smaller than this that compound and can add up to a competitive advantage if we can on average deploy more small positive changes than negative ones.
2. Aligning with future algorithm updates
When we build hypotheses from our understanding of theoretical information retrieval, or from user preferences that we believe Google might move their algorithms towards in the future, we may run tests that are not immediately positive, but that have a positive expected future return.
If we only allow ourselves to deploy changes that are provably beneficial already, we may lose out to competitors who are prepared to act on speculation or announcements of what Google might value more highly in the future.
Potential downsides
Beyond the statistical risks (most obviously, the risk of deploying the occasional change that is actually negative), the biggest strategic challenge to this approach is that when we look back at a sequence of tests and enhancements, we won’t have strong numerical arguments for all of them to compare to their implementation cost. It’s worth remembering that statistical confidence is worth something in the reviews / retrospectives that look at uplifts generated by the activity. We may find some customers push more towards waiting longer for statistical confidence and / or tweaking and re-running tests in search of stronger uplifts because they particularly value this confidence. This is fine, but our default approach is to seek the greatest business benefit for our customers rather than the greatest certainty.
External validation / discussion
One of the other risks with this approach is the chance that serious experimentation teams and individuals with a scientific bent may feel that we are being misleading or dishonest. I believe my suggestions are compatible with their opinions for the most part, but it is easy for misunderstandings to arise, or for us to use language that might cause someone not to trust us.
Key point to note: any language like nearly significant or trending to significance is widely derided and mocked. I have attempted to outline language we should use in situations where we haven’t proved the result we hoped for, but in any case, I believe we should try to avoid this style of talking about our results.
What ends up connecting my view together with the stricter scientific view is two basic facts:
- The 95% threshold is in itself entirely arbitrary. There is no reason in principle why you couldn’t choose 80% or even less as your threshold if you are prepared to accept more false positives
- An inconclusive result is not a proof of no effect, and certainly is not a proof of the opposite effect to the one you hypothesised
Lizzie Eardly presented at CXL Live and gave a passionate talk arguing:

She argued this strongly and strenuously, but her actual advice is not necessarily entirely at odds with my recommendations in this document:

You can read more of the Skyscanner team’s thinking on their experimentation blog in the series they call statistical ghosts (see articles linked from that overview, especially the first in the series).
I think I am mainly arguing that when a test hasn’t reached statistical significance then at worst we should act as if the data is noise rather than the temptation to assume it is evidence that the test has failed.
There is much confusion around hypothesis testing - in particular caused by the language of null which does not mean “no effect” - it refers to the null hypothesis and the p-value which is all about accepting or rejecting said hypothesis. Calling it “null” makes us tempted to assume we have proven that there is no effect when we declare a test null, whereas in fact, we have shown only that it is plausible that the magnitude of effect observed could have come from a situation where there is no real effect (see: The Null Ritual [PDF]). As such, we should seek to refer to tests that do not reach statistical significance as “inconclusive” rather than “null”.
At the same CXL conference, I had a chance to quiz Lukas Vermeer who is in charge of experimentation at Booking.com about the ideas underpinning my argument here. He said that his advice, when someone comes to him with a inconclusive test result off a decent hypothesis is “deploy if you like, but don’t claim you have learned something”. In other words, you can use the strength of the hypothesis to make the case that you should deploy anyway, but don’t use the lower performance thresholds to make the case for additional tests in the same area or for developing new features based on the test.
