
-1-1.png)
In the two-and-a-bit years that I’ve been working in Digital marketing, I’ve been keen to understand the reasons why we make the decisions we do in digital marketing. There’s a wide variety of ways to approach a problem, and although many of them have value, there has to be a best way to make sure that the decision you make is the right one. I wanted to take my evidence-first way of thinking and apply it to this field.
In a previous life, I worked in clinical science, specifically in the field of medical physics. As part of this I was involved in planning and carrying out clinical trials, and came across the concept of a ‘hierarchy of evidence'. In clinical research, this refers to the different standards of evidence that can be used to support a claim – be that a new drug, piece of technology, surgical technique or any other intervention that is claimed to have a beneficial effect – and how they are ranked in terms of strength. There are many different formulations of this hierarchy, but a simple version can be seen here:
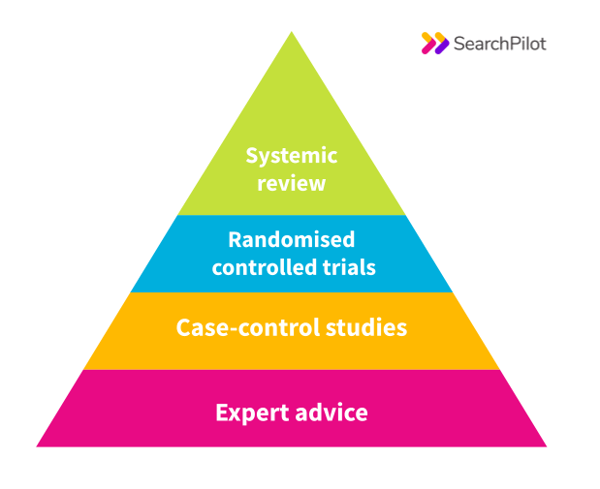
According to this ordering, a systematic review is the best type of evidence. This involves taking a look across all of the evidence provided in clinical trials, and negates the effects of cherry-picking – the practice of using only data that supports your claim, and ignoring negative or neutral results. With a systematic review we can be sure that all of the evidence available is being represented. A randomised controlled trial is a method of removing any extraneous factors from your test, and of making sure that the effect you’re measuring is only due to the intervention you’re making.
This is opposed to case-control reports, which involve looking at historical data of two populations (e.g. people who took one drug vs. another) and seeing what their outcomes were. This has its uses when it is not possible to carry out a proper trial, but it is vulnerable to correlations being misidentified as causation. For example, patients who were prescribed a certain course of treatment may happen to live in more affluent areas and therefore have hundreds of other factors causing them to have better outcomes (better education, nutrition, less other health problems etc.).
All of these types of tests should be viewed as more authoritative than the opinion of anyone, regardless of how experienced or qualified they are. Often bad practices and ideas are carried on without being re-examined for a long time, and the only way we can be sure that something works is to test it. I believe that this is also true in my new field.
A hierarchy of evidence for digital marketing
While working at Distilled [now at SearchPilot, Ed.], I’ve been thinking about how I can apply my evidence-focussed mindset to my new role in digital marketing. I came up with the idea for a hierarchy of evidence for digital marketing that could be applied across all areas. My version looks like this:

A few caveats before I start: this pyramid is by no means comprehensive – there are countless shades of grey between each level, and sometimes something that I’ve put near the bottom will be a better solution for your problem than something at the top.
I’ll start at the bottom and work my way up from worst to best standards of evidence.
Hunches
Obviously, the weakest form of evidence you can use to base any decision on is no evidence at all. That’s what a hunch is – a feeling that may or may not be based on past experience, or just what ‘feels right’. But in my opinion as a cold-hearted scientist, evidence nearly always trumps feelings. Especially when it comes to making good decisions.
Having said that, anyone can fall into the trap of trusting hunches even when better evidence is available.
Best practice
It’s easy to find brilliant advice on the ‘best practice’ for any given intervention in digital marketing. A lot of it is brilliant advice (for example DistilledU) but that does not mean that it is enough. No matter how good best practice advice is, it will never compare to evidence tailored to your specific situation and application. Best practice is applicable to everything, but perfect for nothing.
Best practice is nevertheless a good option when you don’t have the time or resources to perform thorough tests yourself, and it plays a very important role when deciding what direction to push tests in.
Anecdotal evidence
A common mistake in all walks of life is thinking that just because something worked once before, it will work all of the time. This is generally not true – the most important thing is always data, not anecdotes. It’s especially important not to assume that a method that worked once will work again in this field, as we know things are always changing, and every case is wildly different.
As with the above example of best practice advice, anecdotal evidence can be useful when it informs the experimentation you do in the future, but it should not be relied on on its own.
Uncontrolled/badly controlled tests
You’ve decided what intervention you want to make, you’ve enacted it and you’ve measured the results. This sounds like exactly the sort of thing you should be doing, doesn’t it? But you’ve forgotten one key thing – controls! You need something to compare against, to make sure that the changes you’re seeing after your intervention are not due to random chance, or some other change outside of your control that you haven’t accounted for. This is where you need to remember that correlation is not causation!
Almost as bad as not controlling at all is designing your experiment badly, such that your control is meaningless. For example, a sporting goods ecommerce site may make a change to half the pages on its site, and measure the effect on transactions. If the change is made on the ‘cricket’ category just before the cricket season starts, and is compared against the ‘football’ category, you might see a boost in sales for ‘cricket’ which is irrelevant to the changes you made. This is why, when possible, the pages that are changed should be selected randomly, to minimise the effect of biases.
Randomised controlled trials (A/B testing)
The gold standard for almost any field where it’s possible is a randomised controlled trial (RCT). This is true in medicine, and it’s definitely true in digital marketing as well, where they’re generally referred to as A/B tests. This does not mean that RCTs are without flaws, and it is important to set up your trial right to negate any biases that might creep in. It is also vital to understand the statistics involved here. My colleague Tom has written on this recently, and I highly recommend reading his blog post if you’re interested in the technical details.
A/B testing has been used extensively in CRO, paid media and email marketing for a long time, but it has the potential to be extremely valuable in almost any area you can think of. In the last couple of years, we’ve been putting this into practice with SEO, via SearchPilot. It’s incredibly rewarding to walk the walk as well as talking the talk with respect to split testing, and being able to prove for certain that what we’re recommending is the right thing to do for a client.
The reality of testing
Even with a split test that has been set up perfectly, it is still possible to make mistakes. A test can only show you results for things you’re testing for: if you don’t come up with a good intervention to test, you won’t see incredible results. Also, it’s important not to read too much into your results. Once you’ve found something that works brilliantly in your test, don’t assume it will work forever, as things are bound to change soon. The only solution is to test as often as possible.
If you want to know more about the standards of evidence in clinical research and why they’re important, I highly recommend the book Bad Science by Ben Goldacre. If you have anything to add, please do weigh in below the line!