Summary: until November 2021, when it was fixed, googlebot had a bug in how it was interpreting robots.txt files that included XML sitemap links. While the bug was in place, some robots.txt rules would not have been obeyed by googlebot, and when it was fixed, some rules that were previously being ignored might have suddenly come into use for some websites.
Details of the bug
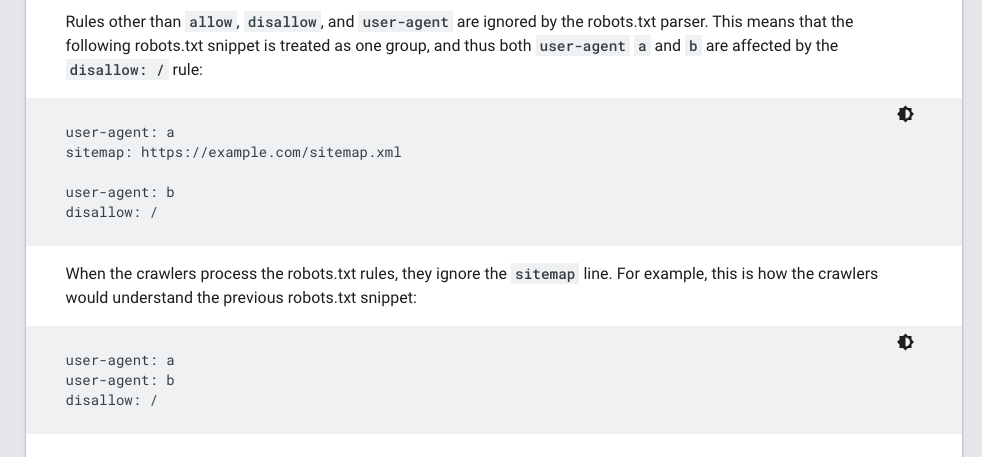
XML sitemap handling is mentioned in the official robots.txt specification, but the details are mainly left up to individual implementations. What it does say, however, is:
a "Sitemaps" record MUST NOT terminate a group.
The Google documentation reiterates that this is how their system works - in line with the specification:
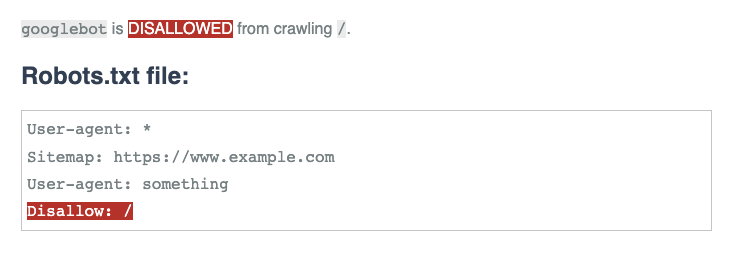
Until the issue was fixed, the sitemap line was not being ignored. If we consider a robots.txt file like the one illustrated:
user-agent: a
sitemap: https://www.example.com/sitemap.xml
user-agent: b
disallow: /
In cases like this, the sitemap line was terminating the group, so that user agent b would be correctly disallowed, but user agent a would not.
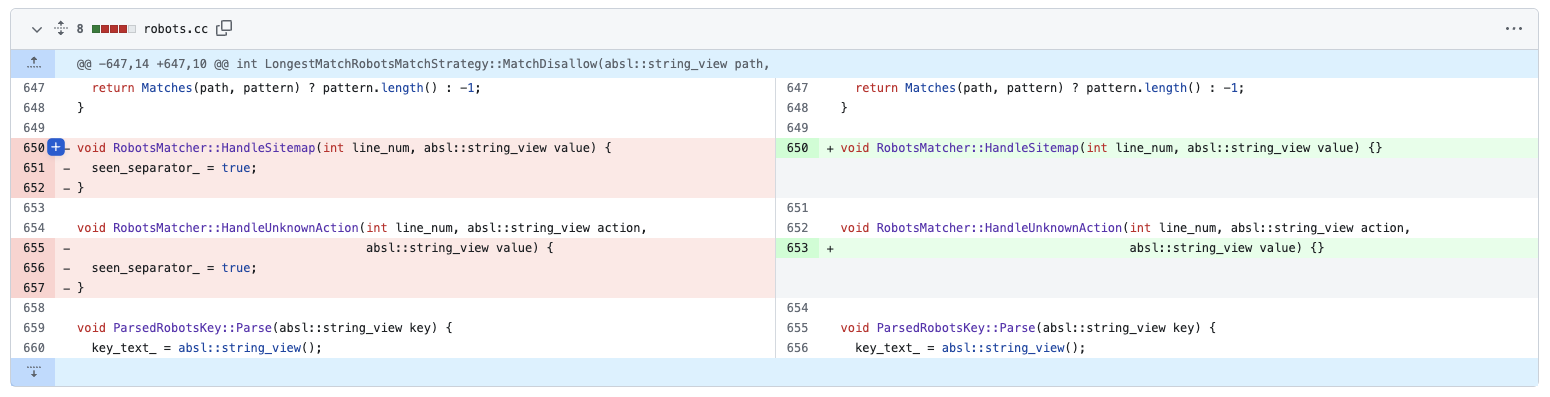
You can see when this was fixed in Google's open source robotstxt repository in November 2021:
As far as I'm aware, this was not picked up and covered in the media. I haven't seen official announcements of it. Since it only just came to my attention, I haven't been able to verify that this bug affected the real googlebot in the wild prior to November 2021, but given all the public statements about this being real code used by googlebot, I can only assume it was. I have reached out to a Google spokesperson for comment and will update this post if I get more information. [Edit: since writing this, I have been reminded of a twitter conversation from July 2021 that confirms this was a real googlebot issue - see postscript at the end of the post].
Impact of the bug
Before this bug was fixed, the impact will have been that some robots.txt files will have had some rules ignored by googlebot. This could have resulted in URLs being crawled that shouldn't have been or vice versa.
In addition, because many public robots.txt testing tools now use the open source parser in order to match googlebot behaviour exactly, they exhibited the same bug as live googlebot prior to November 2021. I found out about the issue because my own project RealRobotsTxt.com exhibited the bug (see below).
What that means is that it's possible that Google fixing the bug has resulted in unintended behaviour - because folks had previously tested their robots.txt files using tools that had the bug present.
Since many such projects (including my own) are not dynamically updated with the latest changes to the open source code, many still exhibit this behaviour (though mine is now fixed) and so it's possible that sites are still getting unintended crawling outcomes due to differences between tools and the (now updated) googlebot.
How I learned about the bug
Fabio Andreotti dropped me an email to let me know that he and his colleague Lorenzo Lemmi had discovered a bug on RealRobotsTxt.com. They had verified that real googlebot was behaving correctly, but various testing tools including mine were susceptible to the issue described above.
I started off down a rabbit hole of thinking that real googlebot must not be using the open source robots.txt parser despite the official claims. I had some difficulty building the latest version of the open source parser to test it for myself, but eventually got it built and discovered that its behaviour no longer matched my tool's.
At this point, I started digging through the changes and differences between my web version and the latest open source version and found the November 2021 fix.
What you should do now
I have now updated my project so that it once again uses the latest version of the open source code which means it should once again match live googlebot behaviour:
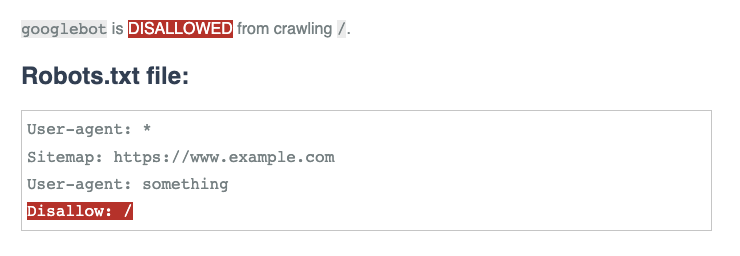
If you think that your robots.txt file could be impacted by this change, I would therefore encourage you to retest it using the latest version.
Other changes to the open source parser
I haven't yet done a detailed review of all the changes Google has made to the open source parser since launch. Most are changes to the documentation or changes to stay compatible with changes to other libraries. The only other interesting code change I've noticed apart from the bug fix outlined above is a change to return different codes depending on the outcome of the robots.txt file evaluation which makes it easier to use programmatically.
I was, however, pleased to see this change to the documentation which clarified that bots like googlebot-image use "implementation logic" outside of the open source library which I had felt wasn't clear when the project was originally released.
As always, I'm far too interested in robots.txt for my own sanity, so please do message me on your social platform of choice to discuss if you're interested - I'm @willcritchlow pretty much everywhere.
Postscript:
I was reminded on twitter that we had actually looked at this issue back in July 2021 when my tool, the open source parser, and googlebot were all "wrong" compared to the documentation. This clarifies that this was a bug with real googlebot and not just in the open source parser. Thank you @MattTutt1 for the reminder and @maxxeight for the discussion.

.png)