Ever heard of the “French Paradox”? If you’re a red wine drinker and don’t want bad news, look away now.
In the 1980s, French scientists noticed a negative correlation between the amount of saturated fats the French had in their diet and their relatively low levels of coronary heart disease. Hence, the French Paradox. In an attempt to find out why, a bunch of studies looked at what was unique about the French that might explain it. One observation was that the French drank more red wine per capita than any other country. It’s now Portugal if you’re interested.
“It seemed, for a glorious few years, that we could gorge on cheese and saucisson, and then unclog our arteries with a bottle of claret.” Source
As you might expect, this turned out not to be the case and demonstrates nicely the adage that correlation does not equal causation. The observations don’t account for other factors at play, for example, that the French also had a healthier diet than other countries at the time or that eating lots of saturated fats was quite new for the French and developing heart disease can take decades.
So why am I talking about this? Because I see a lot of the same kinds of mistakes being made when it comes to SEO testing. I think at least some of that has to do with confusion or ambiguity around what is classed as SEO testing. So, let’s start with that. For a deeper dive into all things to do with SEO A/B testing, read our guide What is SEO Testing.
SEO Testing Methodologies
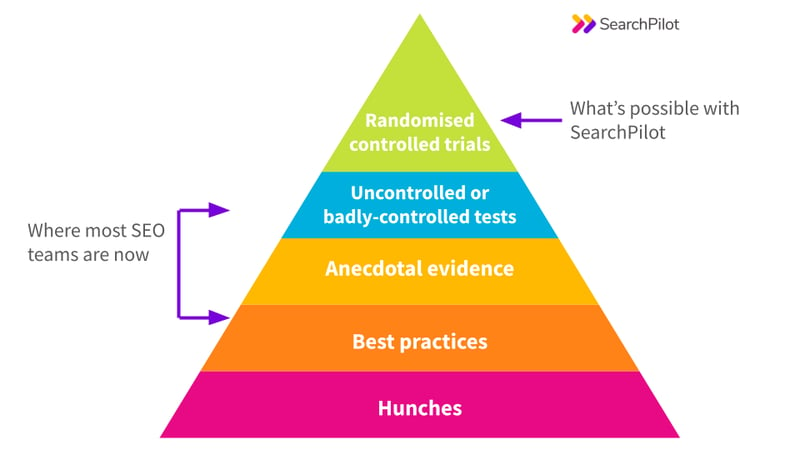
In clinical research, the robustness of your testing methodology is classified according to the ‘hierarchy of evidence’. My colleague Sam Nemzer wrote about this in The Hierarchy of Evidence for Digital Marketing Testing.
Using SEO split testing software like SearchPilot to run randomised controlled experiments hasn’t always been an option. Instead, SEOs have had to rely on their hunches, best practices, or poorly controlled tests to reverse engineer Google. But it doesn’t need to be that way.
.png?width=960&height=540&name=Hierarchy%20of%20evidence%20(2).png)
What we see in the SEO world, casually referred to as testing, is often just anecdotal evidence or badly controlled tests. In some cases, this might be all that is possible, but it’s helpful to know the limits of each so you can make an informed decision.
Here are some examples of tests that I’d be wary of broken into two categories, badly controlled vs observational.
Badly controlled tests
- Quasi-experiments are when you only change a set of pages with a common property. For instance, you might change the meta description on only product pages or only on pages older than 2 years old. You then compare the changes in traffic to pages that have not had the treatment. The thing that makes this a quasi-experiment is that the pages are not randomised. You are preselecting the pages based on a particular characteristic. This leaves the likelihood of the test being flawed because of a prior bias.
- Before-and-after studies, also known as pre-post studies, are when you change a group of pages without any randomisation or a control group to compare against. An example would be adding structured data to all of your product pages and measuring the impact on traffic, rankings or click-through rates. The problem with this kind of test is it doesn’t consider the impact of external factors like seasonality, algorithm changes, competitors or backlinks to name just a few. When we have analysed these kinds of changes, we have found that the confounding effects are typically larger than the effects you are trying to measure.
- Single-case experiments are when you change something about a single page. For instance, a title tag or H1, then track the impact on traffic and rankings. This might be used in instances where it’s not possible to have a group. For example, blog post titles are all different, but you might still try to increase click-through rates by updating titles. The downside to this approach is the lack of controls. Similar to the pre-post test example above, this can’t account for external factors and is subject to even more noise.
Observational tests
- Case-control studies are backwards-looking. You find cases of some behaviour, for instance, a group of pages that have all increased or decreased in rankings, and compare them against pages that you deem similar but haven’t seen the same increase or decrease. The goal would be to identify common factors that might have contributed to the impact. We often see this sort of analysis around Google updates. Maybe you identified pages with bad CWV scores or that have too many adverts on them. The downside of this approach is that there’s no way to know the cause without further controlled tests. The change might have been caused by the issues you suspect, it could be because of something you are unaware of, or it could be random - especially if you are hunting for this kind of change retrospectively.
- Cross-sectional studies have some use in showing correlation at a point in time but aren’t helpful in understanding causality. For instance, you might gather lots of data points about sites in the top 10 results of Google, like the number of backlinks, site speed, word count, etc., and then use this to spot commonalities. For instance, you might say that all results in the top 10 have the keyword in the domain, but it’s impossible to tell from this alone whether the keyword is causing the high ranking. This kind of study is particularly susceptible to reversal of causality or features with common causes (e.g. ice cream consumption and sunny days go together but ice cream consumption doesn’t cause sunshine, and ice cream sales and sun cream sales both rise and fall together, but neither causes the other).
- Observational studies tend to be used where you can’t or wouldn’t want to create an intervention. For example, suppose you think building links from low-quality websites might damage your Google rankings. You wouldn’t want to build bad links just to find out you were correct. Instead, you might design an experiment where you take a group of websites that are already building low-quality links and observe them over time to find out if there were noticeable performance differences compared to a control group. The downside of this test design is that it can’t establish causality because there could be other factors causing the difference, but it can be helpful for directional evidence.
- Lab studies would be setting up a dummy website to test a theory, for example, the impact of canonical tags. This approach has the benefit of no risk to your actual site, but the downside is that it’s still a form of observational study, and the learnings may not translate to the same outcome for your actual website. Lab studies can still be useful for learning and informing future controlled tests.
How to do it better - randomised controlled experiments for SEO
If your goal is to determine causal relationships (and it should be), randomised controlled experiments are widely considered the best way to do that.
In a randomised controlled experiment, a representative sample of the population you care about is randomly divided into either control subjects or variants.
The advantage of randomisation is that it helps control for any bias in the bucketing. That’s not to say the other forms of testing aren’t useful. or example, they can be great ways of coming up with test ideas, but you need to be aware of their limitations.
In the SEO world, the “population” that we care about is a population of pages, not people. Even still, the process is the same. Pages should be randomly assigned as a control or variant page. Without randomisation, you could accidentally (or deliberately) exaggerate the impact of a test on sessions, rankings or click through rates.
Some examples of ways you could unknowingly bias an experiment before it’s begun could be:
- Putting too many old or new pages into one bucket
- Putting too many high or low-traffic pages into one bucket
- Putting too many pages with the most amount of backlinks into one bucket
- Putting too many best-selling product pages into one bucket
- Putting too many seasonal products into one bucket
Those are just some examples, but it’s easy to imagine almost unlimited ways the test could be skewed. That’s why when designing your own tests or evaluating the results of other peoples’ results, it’s important to make note of the methodology and ensure the pages were randomly assigned.

SearchPilot makes this process easy by automatically creating smart buckets for you (learn more about smart bucketing in this post: How smart bucketing can strengthen your SEO testing approach and deliver accurate traffic data) when you set up a test.
You can design tests with three steps:
- Creating the randomly assigned buckets
- Making the change you want to test to the variant pages only
- Analysing the results
You can do this using SearchPilot very quickly. The result is that you get results that you can trust and learn from. If you want to see some examples of SEO tests, look at our case studies and customer stories. If you’d like to learn more about how SearchPilot can help you get your testing program up and running, get in touch with our team.
.png)