
-1-2.jpg)
It’s always bugged us that so many recommendations get shoved in a drawer and never seen again. I remember the repeated pain in the early years as we found ourselves getting surprised again and again by the clients who would commission us to create some in-depth audit, and then never make the changes we were recommending. As we spoke to friends and colleagues around the industry, we came to realise that we were far from alone in this. Indeed, we often come across in-house teams with multiple audit documents gently gathering dust, and with huge backlogs and waitlists even for high-priority changes.
Our obsession with figuring out how to have an actual business impact for our clients meant that this was really troubling for us - after all, a recommendation that never gets implemented can never make a difference.
I really feel at this point that we’ve seen pretty much every reason under the sun for why recommendations fail to break through, made all kinds of mistakes, and we see many of the same reasons again and again. Some of the more common ones include:
-
We didn’t communicate the recommendations clearly enough [see: how to write better business documents]
-
We failed to consider the (good or bad) reasons why things are the way they are
-
We failed to understand the difficulty of what we are recommending (often characterised by the suggestion “you should just…“)
-
We didn’t back recommendations up with good enough reasoning (which, depending on the magnitude of the change could be anything from logic to case studies to full on business cases)
For #1 we obsess about communication at least as much as we obsess about effectiveness.
#2 is all about getting close to the client, asking the right questions and developing core consulting skills.
#3 and #4 are two that we are attacking at SearchPilot - by making it easy and fast to roll out SEO changes, and introducing the ability to split-test on-site changes and measure their impact.
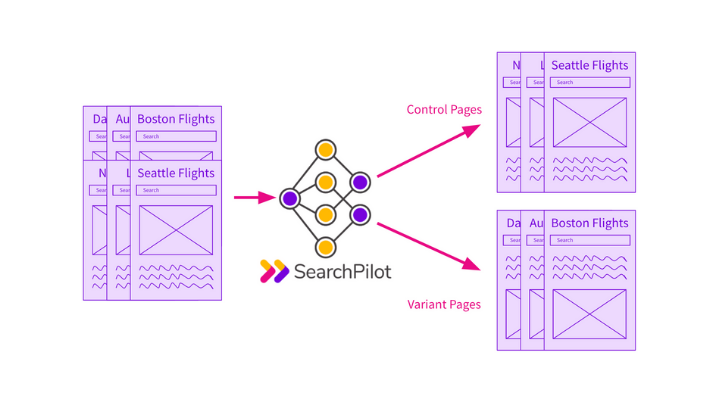
It’s that last point that is changing the way I am thinking about what consulting even is. The ability to split-test changes, and to apply statistical analysis to measure the results is changing the kind of recommendations I’m making.
How split-testing changes everything
We started out thinking that by building a split-testing platform that we were attacking issue #4 above - that the benefit of split-testing would be in the ability to build business cases.
And that is a huge benefit and a great opportunity to put engineering teams to work only on the biggest and most impactful of enhancements.
But there’s a more subtle change that I’ve noticed in the course of building out these tests for customers and prospects: we are going to end up making entirely different sets of recommendations to those we have been making.
The obvious effect is that we are going to have the ability to stop having people waste their time on “best practice” changes that don’t actually make a real difference to our clients’ businesses. Where other agencies will continue delivering laundry lists of things that are theoretically wrong with a site, we will be able to use scientific data from our experiments to select the best tests to run first, and then use the outcomes of those tests to make the case for allocating engineering resource.
So far so uninteresting.
There is another mindset change, though - one that I hadn’t really expected - which is that I find myself recommending tests to clients that I’d never have recommended as part of an audit or engagement without the split-testing capability.
There are a few different kinds of these new recommendations:
-
The small upside
-
The unknown effect
-
The possible downside
…and I thought I’d describe each of them in turn and highlight why I think they’re going to change the way we think about on-site SEO:
The small upside
There’s a whole class of tweaks that I wouldn’t normally bother a client with. You know the type of thing - you just feel like you’re nitpicking if you suggest them, and you know you don’t have a good answer to the inevitable question “is it worth it?” or “is that really going to make a difference?”.
When you can push out a whole bunch of these tweaks along with the measurement to tell if they work, you can bother the engineering team only with the ones that are worth it, and you can get a compounding effect from the aggregation of marginal gains.
In addition to technical changes, another example of this kind of thing is tweaks I’ve been finding myself wanting to test to keyword targeting. These are the kinds of change that typically sit well below the level of the granularity of data we get from keyword research tools, and anyway, even if we had the data, we wouldn’t be able to judge the trade-off between the possible reduction in focus and the addition of new keyword targeting to the page.
Examples include:
-
Adding “2016” to the keyword targeting of certain kinds of pages. Does the search volume for those kinds of keywords outweigh any possible downsides - confusion for users, dilution of focus etc? Who knows until we test
-
Attempts to improve the clickthrough rate from the organic search results. What will appeal to searchers? Can we effectively control the “organic ad” or is Google going to override the meta information on the page? We have no idea until we test
These are not the kinds of test we can run in theory on test sites and extrapolate to the real world. They are context-specific, and they rely on testing against real users on the real site.
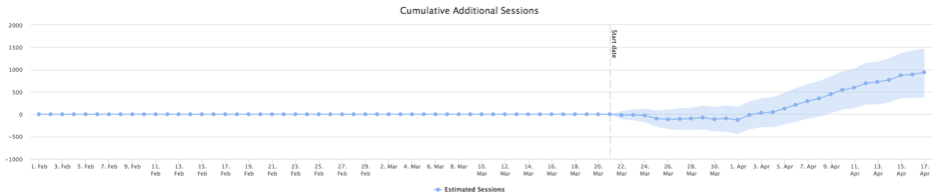
An example of a ‘small upside’ test we carried out recently.
The unknown effect
None of us knows how Google really works. We cobble together information from experience, experiments, published data, first principles, and official lines, but we don’t really know. Especially when we’re working from first principles, we often find ourselves with a theory of something that could be a factor, but might make no difference at all.
I have been surprised to find myself wanting to test changes that have no particular grounding in things I’ve seen work in the real world before. I’d have been unable to justify recommending this kind of thing to clients in the past - not only because the engineering work could well be wasted, but more importantly because we couldn’t tell. When there’s so much noise and randomness, seasonality, and external effects (from Google changes and competitors’ actions), it’s really hard to unpick the effect of changes without controlled experiments and fancy maths.
The possible downside
There are times when you want to make a change - for user experience or conversion rate reasons - but you are worried that the net impact could be negative. Perhaps you are reducing the keyword targeting in order to improve the call to action - does the improvement in conversion rate make up for a potential reduction in organic traffic? Perhaps someone in the org wants to use a JavaScript framework, and you aren’t sure if you can trust the crawler’s JS rendering or if you’re going to need to pre-render.
By rolling out the change to a “taste test” of just a small fraction of pages in a section, and monitoring the impact with a split test, you can take these risks, look for the upsides, and avoid the worst cases of drops in performance. Pinterest talked about this in their ground-breaking post.
In summary
I expected split-testing to help us build business cases and hence get things done - something that’s so central to what we are trying to do. What I didn’t expect was the way that having the ability to test is encouraging me to suggest whole new classes of change that I would never have been able to justify, or would have been too nervous to suggest before now.
I look forward to the day when we’ve run enough of them, and gathered enough data, that we can start to debunk best practices that repeatedly fail to pay off and double-down on recommendations that always outperform. I’m sure we’ll write those up when we get to that point so drop your email in here if you want to stay up to date.
Get in touch if you want to be able to split test
Can you split test SEO changes? If you’re interested in seeing a demo of our split testing platform, get in touch.
This is the future of our technical and on-site recommendations. It could be the future of yours as well.